
Welcome to SDGym!
The Synthetic Data Gym (SDGym) is a Python library for benchmarking different synthetic data generators. For example you can compare synthesizers that use classical statistics versus those that use deep learning.
Why benchmarking?
The past few years have seen an increasing amount of research in the synthetic data space. With such a variety of models available, we feel that it's important to validate new techniques with a proper framework in place.
We built SDGym as flexible and customizable framework that you can use for a thorough analysis of synthetic data. This will give you the confidence when publishing your results and incorporating synthetic data into your projects.
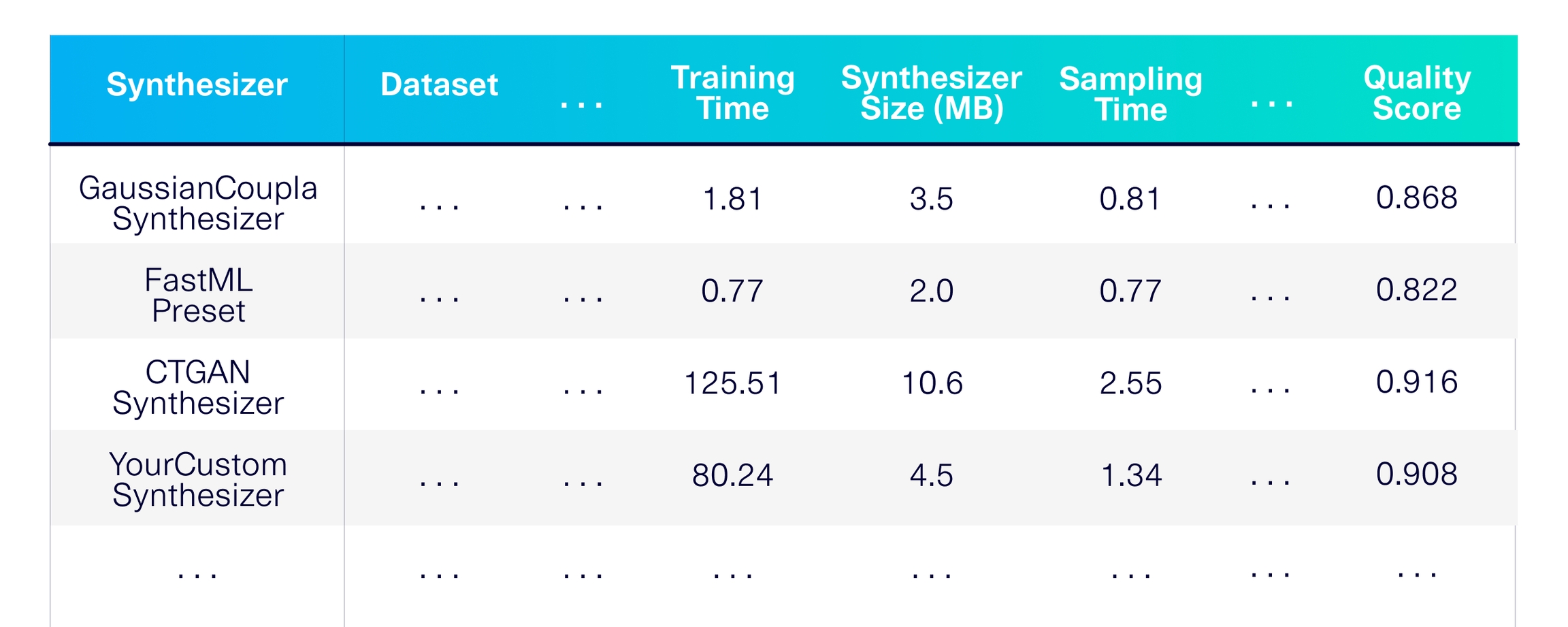
🧮 Use multiple datasets for a reliable benchmark
If your goal is to test a robust synthetic data model, relying on a single dataset may not give you much confidence. The SDGym library comes with a variety of publicly available datasets that are immediately for use.
This is helpful for detecting errors in your synthesizer as well as identifying its strengths and weaknesses.
⚙️ Customize your benchmarking framework
We recognize that benchmarking may not be a one-size-fits-all solution. Our framework allows you to input your own custom datasets if you are working with private data.
You can also customize your evaluation metrics by selecting any metric in the SDMetrics library.
Get started
Install the sdgym software and kick off a benchmarking run in only 2 lines of code!
Owned & Maintained by DataCebo
The SDGym library is a part of the Synthetic Data Vault Project, first created at MIT's Data to AI Lab in 2016. After 4 years of research and traction with enterprise, we created DataCebo in 2020 with the goal of growing the project.
Today, DataCebo is the proud developer of the SDV, the largest ecosystem for synthetic data generation & evaluation.
Last updated
{kind=link}